

剪辑:剪辑部 HXZ成人快播网站
随OpenAI爆火的CoT,也曾激勉了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT不错让Transformer推理暧昧限。但就地他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确旅途吗?
跟着OpenAI o1的爆火,最近CoT也成了圈内热议的高频词。
靠着CoT的强力加持,o1奏凯在LLM限度初度完毕了通用复杂推理才气,俨然是AI发展新范式的最先。
许多东谈主惊呼:莫非CoT便是通往AGI的正确旅途?
何况,o1这种慢想考模式不仅匡助LLM作念数学和象征推理,致使,还让LLM发展出了类情面感!
最近,斯坦福等机构学者发文阐述:LLM在面容方面阐发出的领路和推理比东谈主类还像东谈主类,背后最大孝敬者果然便是CoT。

就在这几天,风口浪尖上的CoT,又让AI社区掀翻了一场风云。
谷歌DeepMind首席科学家称LLM推理暧昧限,LeCun田渊栋回怼
CoT爆火之后,谷歌DeepMind首席科学家Denny Zhou拿出了我方团队八月份的一篇论文,抛出了这么的不雅点:「LLM推理才气的极限是什么?那便是莫得浪漫」。
他表露,谷歌团队也曾用数学法子解说,Transformer不错贬株连何问题,惟有允许它们证据需要生成淘气数目的中间推理token。

不错看出,Denny Zhou等东谈主建议的中间推理token,跟o1的中枢技艺CoT绝顶相似。
传统的Transformer模子的致命瑕疵,便是擅长并行野心,但不擅长串行推理。
而CoT,赶巧贬责了这个问题。
在这项责任中,Denny Zhou等东谈主发现:传统的Transformer模子,只可贬责AC0电路能贬责的问题;但一朝加入CoT,Transformer险些不错贬株连何问题。

惟有CoT才气充足多,Transformer就能模拟淘气大小的布尔电路,贬责P/poly问题
也便是说,不错用数学严格解说,CoT不错让Transformer贬责险些所有能用野神思贬责的问题。

欺诈CoT,不错模拟布尔电路中每个逻辑门的野心
这项责任表露着,CoT为更渊博的LLM推理提供了新的想路,CoT或将成为昔日LLM发展的蹙迫标的,何况很可能精通着AGI的火花。
Denny Zhou发帖后,立即激勉了AI社区的热议。
多位辩论者下场讨论,也惊动了其他大佬。
这不,就在刚刚,田渊栋和LeCun循序发表意见,回怼了Denny Zhou。
在他们看来,CoT的作用,被远远夸大了。

田渊栋表露,天然CoT简直很有用,但Denny Zhou等东谈主对其过于盲目追捧了,昭彰,CoT并不是咱们所需要的一切。
在这篇论文中提到的是一种通用表面,不错通过显式构建Transformer权重,让其更好地稳当特定任务。
可是这么,CoT的长度就会很长,这么的权重确立,能否通过梯度着落来学习呢?
表面上,2层多层感知器是不错拟合任何数据的,那咱们就该信赖它不错应用在所有场景中吗?
东谈主类的推练链是十分精真金不怕火的,濒临从未见过的问题,也能捕捉关节身分。但LLM不错吗?
如安在一会儿就学习或构建出这么的表征,是很乐不思蜀的。
田渊栋的帖子一发出,坐窝就获取了LeCun的支撑。

LeCun表露,我方原本也想发表肖似的言论,不巧被田渊栋抢先了。
「2层网罗和核机器不错无限靠拢任何函数,达到咱们想要的精度,是以咱们不需要深度学习。」
从1995年到2010年,LeCun听到这个说法无数遍了。
天然,这个操作表面上是可行的。但若是真是在扩充中应用所有干系的函数,光是第一层中的神经元数目就会多到不可想议。
对此,网友的评价是:遏抑和等价解说被高估了,高效的学习政策被低估了,便是这么。
「我很欢乐Python的存在,尽管Pascal是图灵完备的。」

一位从业者表露,我方的辩论是从一个笼罩层MLP判别式出手,然后便是CNN或Deep NN等专科模子。
他的判断是:较小的模子更谨慎、更可解释成人快播网站,何况频繁很接近,但遥远不会那么好。而使用更深档次的模子,老是会有颠倒的百分比。
好多东谈主是「挺CoT派」的。比如有东谈主表露深刻LeCun的不雅点,但在多维膨胀场景中,CoT全皆大有后劲。

而对于LeCun所惦记的问题,有网友表露,LeCun在摄取一种从上至下的政策,在这种情况下他必须适度所有的第一层输入,但其实,他并不需要。

因为,CoT通过创建了新的临时层,让东谈主消灭了对这种适度的幻想。其贬责决策便是,通过网罗层的一般格式,来靠拢看重力头自身。
道理的是,该网友表露,我方的灵感开首是《物理学》上的一封信,标明量子全息拓扑能更灵验地自豪这一丝。
即使爱因斯坦-罗森桥的领域相配大,它不错更说合地翻脸表露为无数不同的小层,横跨所产生的平坦空间。这,便是表征的力量场所。

有东谈主表露,这个讨论没什么道理,骨子上不外是「无限山公定理」收场。
让一只山公在打字机上有时按键,当按键期间达到无限时,险些势必能打出任何给定笔墨,比如莎士比亚全集。

田渊栋:不错发展,但更复杂
最终,田渊栋也承认,谷歌这篇论文的想路简直有可取之处。可是由于触及到不同的数据散播、模子架构、学习算法、后处理等等,问题还要更复杂。
正如Evolutionary Scale联创Zeming Lin所言:咱们需要像乔姆斯下档次结构这么的机器学习模子。就像ML模子有NP、P、O(n^2) 等主见相似,Transformer或Mamba属于那里呢?

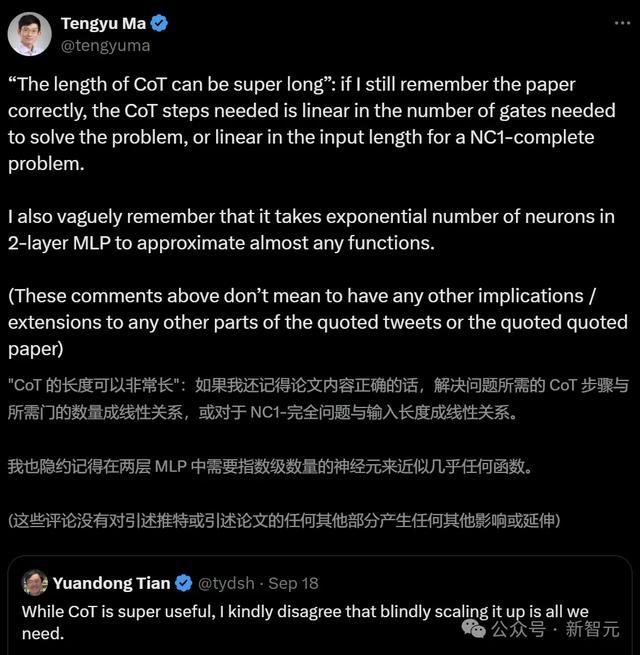
而在田渊栋发帖的第二天,谷歌论文主要作家马腾宇也上线指摘述:CoT的长度是不错超长的。
2层MLP中的神经元数目呈指数级,才能靠拢险些任何函数。
田渊栋回话他说:对那些可能需要指数数目的门的问题,CoT的长度不错很长。
这和2层MLP情况是一致的,因为无论拟合淘气函数,皆需要覆盖高维空间中的所有角,这是最坏的情况。
可是,现实宇宙的问题,是否有如斯精雅/精真金不怕火的表征呢?若是它们皆像NC1相似,属于P问题,那么天然不错通过构建Transformer的权重来作念到。

在最近一条X帖子中,田渊栋表露,我方的办法是,大约找到更短的CoT,同期使用巨匠迭代(穷东谈主的RL)来保持最好恶果。
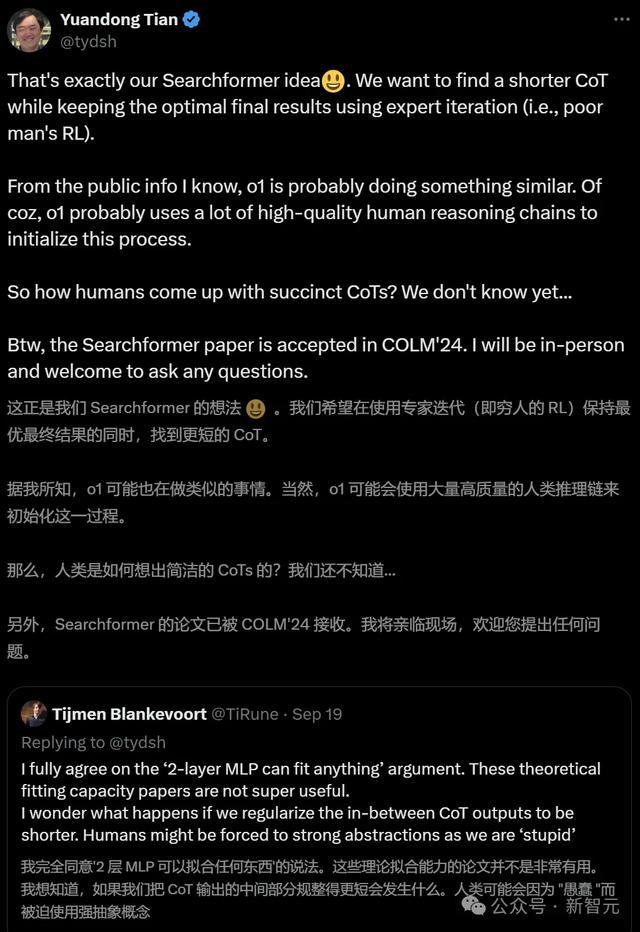
从公开信息来看,他意想o1亦然在作念肖似的事情。至于驱动化历程,可能是使用了无数高质地的东谈主类推理链。
东谈主类是如何想出精真金不怕火的CoT呢,这就不为东谈主所知了。
趁此契机,他还宣传了一下我方团队Searchformer的论文。

论文地址:https://arxiv.org/abs/2402.14083
总之,天然咱们还不知谈如何拓展2层神经网罗,但OpenAI似乎驯服我方也曾掌捏了拓展CoT的诀窍。

最新讲座:揭示LLM推理的关节想想和局限
当今,这场空前强横的讨论还在无间。
而对于LLM推理,Denny Zhou最近在UC伯克利也进行了一场肖似主题的讲座。

他表露,我方对AI的期待是不错像东谈主类相似从较少的示例中进行学习。

但也曾尝试的万般机器学习法子之是以皆不告捷,是因为模子缺失了一种蹙迫才气——推理。

东谈主类之是以能从较少的示例中学习到轮廓的划定和道理,便是因为推理才气。正如爱因斯坦所说的,「Make things as simple as possible but not simpler」。(一切皆应该尽可能浮浅,但不成过于浮浅)
比如,对于底下这个问题:

对东谈主类而言,这是全部小学水平的「找划定」。
但机器学习需要海量的标注数据才能找出其中的划定。
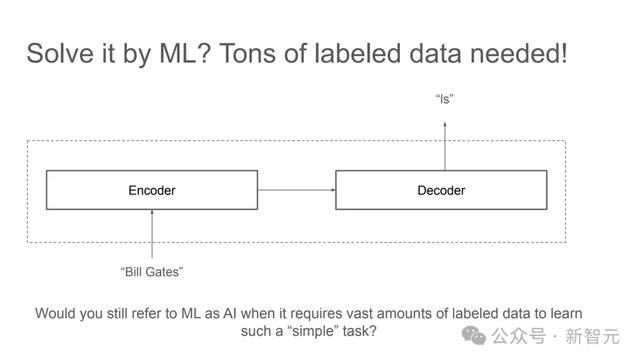
而LLM的少样本学习更是难以贬责。

但若是在数据中加入「推理历程」,LLM就很容易有样学样,学习到极少样本示例中展现出的划定,并给出正确谜底。

通过这个浮浅的例子,Denny Zhou指出,关节办法是在数据中包含中间才气,或者是解释道理(rationale),同期让模子写出推导历程。
这便是使用CoT背后的逻辑和直观。
「中间才气」,为若何此蹙迫
DeepMind的辩论者们,最初使用天然说话道理去贬责数知识题。
关节就在于重新出手测验了一个序列到序列模子,从而通过一系列小才气得出最终谜底。

继这项责任后,OpenAI的辩论者们建设了一个更大的数学单词问题数据集(GSM8K),其中包含天然说话基本道理,并欺诈它对GPT-3进行了微调。

这么,说话模子的中间野心才气,就被展示了出来。

o1模子的奠基性孝敬者之一Jason Wei在谷歌大脑责任时曾和Denny Zhou发表了一篇论文,指出CoT请示不错投合出LLM的推理才气。

Denny Zhou致使更直白地指出样本「中间才气」的蹙迫性:无论是测验、微调如故请示,皆需要给出中间才气,才能让LLM在反映中也包含中间才气。

执行上,这亦然Denny Zhou、马腾宇最近论文的中枢不雅点。若是能生成充足长的中间推理才气,常数深度的Transformer模子也能贬株连何串行问题。

CoT并不是一切
但是,这也并不虞味着CoT不错包打一切,贬责LLM推理的所有颓势。
比如,模子很容易被无关的坎坷文干与,这一丝和东谈主类想维也很肖似。
实验中发现,在GSM8K数据聚积添加无关坎坷文,不错导致模子性能出现高达20+百分点的亏损。

此外,LLM的自我改良才气也并不健全。
天然有些模子在反想后不错告捷修改失误谜底,但也存在另一种风险——可能反而把正确谜底改错。

那么,LLM的下一步应该往何处去?
Denny Zhou指出,天然咱们也曾知谈了模子推理有哪些颓势和不及,但最蹙迫的如故界说好问题,再从第一性道理起程去贬责。

此处,再援用一句爱因斯坦的话:「若是有1小时用来救助星球,我会花59分钟来界说问题,然后用1分钟贬责它。」
一些质疑
天然Denny Zhou的演讲内容相配详确,但「CoT完毕推理暧昧限」的结论如实相配斗胆,因此也引起了网友的反驳。
比如有东谈主指出,前提中所谓的「无限多token」仅仅在表面上可行,在扩充中未必如斯。
token数目很有可能随输入增多呈现指数增长,问题变得越来越复杂时,token数目靠拢无限,你要若何处理?

何况,LLM推理和东谈主类还存在骨子各异。AI当今只可进行暴力搜索(brute-force),但东谈主类有所谓的「启发式」想考,「直观」让咱们能将数百万种可能性快速缩减至几种可行的贬责决策。

若是想达到AGI成人快播网站,AI系统就需要模拟出这种高效的问题贬责旅途。